Рис. 1
Методы внешней сортировки по Д. Кнуту
© 1973 Donald E. Knuth, Stanford University Publishers
© 1978 Издательство «Мир», перевод и переиздание
© 2001 Григорьев Г, группа П-13, перепечатка, редактирование и распространение в WEB
Введение
Интересные задачи возникают, если число сортируемых записей превышает объем быстродействующего ОЗУ. Внешняя сортировка в корне отлична от внутренней (хотя в обоих случаях необходимо расположить записи данного файла в указанном порядке), и объясняется это тем, что время доступа к файлам на внешних носителях нас жесточайшим образом лимитирует. Структура данных должна быть такой, чтобы сравнительно медленные периферийные запоминающие устройства могли справиться с потребностями алгоритмов сортировки. Поэтому большинство методов внутренней сортировки (вставка, обмен, выбор и пр.) фактически бесполезно для внешней сортировки; необходимо рассмотреть всю проблему заново.
Предположим, например, что предназначенный для сортировки файл состоит из 5000 записей R
1, R2, …, R5000 длиной по 20 слов (ключи Ri могут быть и не такой длины). Как быть, если во внутренней памяти машины помещается одновременно только 1000 из этих записей?Сразу напрашивается такое решение: начать с сортировки каждого из 5 подфайлов R
1 - R1000, R1001 - R2000, … , R4001 - R5000 по отдельности и затем слить полученные подфайлы. К счастью, слияние оперирует только очень простыми структурами данных, а именно, линейными списками, пройти которые можно последовательным образом, как, например, стеки или очереди. Поэтому для слияния годятся самые дешевые запоминающие устройства.Только что описанный процесс - внутренняя сортировка с последующим "внешним слиянием" - весьма популярен, и, предположительно, достаточно интуитивен, чтобы объяснять его.
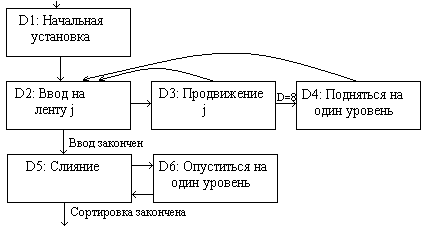
Пусть имеется Р возрастающих отрезков, т.е. последовательность записей, ключи которых расположены в неубывающем порядке. Очевидным способом их слияния будет следующий: посмотреть на первые записи каждого отрезка и выбрать из них ту, которой соответствует минимальный ключ; эта запись передается на выход и исключается из входных данных, затем процесс повторяется.
Пока Р не слишком велико, этот выбор удобно осуществлять, просто выполняя (Р-1) сравнений для нахождения наименьшего из текущих ключей. Но если, скажем, Р
і 8, то можно сократить работу, используя дерево выбора (подробнее об этом - в разделе "Методы внутренней сортировки" того же издания), тогда каждый раз требуется » log2P сравнений (после начального форматирования дерева). Рассмотрим, например, четырехпутевое слияние с двухуровневым деревом выбора:|
|
|
Рис. 1 |
В этом примере в конце каждого отрезка помещен добавочный ключ
Ґ, чтобы слияние заканчивалось естественно. Так как внешнее слияние обычно имеет дело с очень длинными отрезками, то эта добавочная запись с ключом Ґ существенно не увеличит длину данных или объем работы при слиянии; кроме того, такая "концевая" запись часто служит удобным способом разделения записей файла.В рассматриваемом процессе (рис. 1) каждый шаг, кроме первого, состоит из замещения наименьшего элемента следующим элементом из этого же отрезка и изменения соответствующего пути в дереве выбора. Так, на шаге 2 изменяется 3 узла, которые содержали 087 на шаге 1; на шаге 3 изменяется 3 узла, содержавшие 15
4 на шаге 2, и т.д. Процесс замещения в дереве выбора одного ключа другим называется выбором с замещением.Мы можем по-разному рассматривать приведенное четырехпутевое слияние. С одной точки зрения оно эквивалентно двум двухпутевым слияниям, выполняемым совместно, как сопрограммы; каждый узел дерева изображает одну из последовательностей, используемых в процессах слияния. Дерево выбора, по существу, используется как приоритетная очередь с дисциплиной "наименьшим из включенных первым исключается".
|
|
|
Рис.2 Турнир, при котором выбирается наименьший ключ; используется полное бинарное дерево, узлы которого пронумерованы от 1 до 23 |
Дерево проигравших.
На рисунке 2 изображено полной бинарное дерево с 12 листьями (квадратными) и 11 узлами (круглыми); в листьях записаны ключи, в узлах - "победители", если дерево рассматривать как турнир для выбора наименьшего ключа. Числа меньшего размера над каждым узлом показывают традиционный способ распределения последовательных позиций памяти для полного бинарного дерева.Чтобы определить новое состояние дерева выбора, изображенного на рис. 2, когда наименьший ключ 061 будет заменен другим ключом, нужно рассмотреть только ключи 512, 084 и 154, и никакие другие. Если интерпретировать дерево как турнир, последние три ключа будут представлять собой проигравших в матчах с игроком 061. Это наводит на мысль, что мы в действительности должны записать во внутренние узлы проигравшего в каждом матче, а не победителя, тогда информация, необходимая для изменения дерева, будет легкодоступной.
|
|
|
Рис 3 Тот же турнир, что и на рис.2, но показаны проигравшие, а не победители; чемпион находится на самом верху |
На рис. 3 изображено то же дерево, что и на рис. 2, но вместо победителей в нем представлены проигравшие. Дополнительный узел с номером "0" добавлен на вершине дерева для указания чемпиона турнира.
На практике внешним узлам в нижней части рис. 3 будут соответствовать весьма длинные записи, расположенные в памяти ПК, а внутренним узлам - указатели на эти записи. Заметим, что Р-путевое слияние требует ровно Р внешних и Р внутренних узлов по одному в соседних группах, что наводит на мысль о более эффективных методах распределения памяти
. Нетрудно видеть, каким образом можно использовать дерево проигравших для выбора с замещением.Предположим, что в нашем распоряжении имеются три внешних
устройства Т1, Т2 и Т3. Теперь можно воспользоваться сбалансированным слиянием, описанным выше для Р=2 и Т=3. Оно принимает следующий вид:Ш1: Распределить начальные отрезки попеременно на Т1, Т2 и Т3
Ш2: Слить отрезки с устройств Т1 и Т2 на Т3; затем остановиться, если Т3 содержит только один отрезок.
Ш3: Скопировать отрезки с Т3 попеременно на Т1 и Т2, затем вернуться к шагу Ш2.
Первый проход слияния приведет к S/2 отрезкам (если первоначально их было S) на Т3, второй - к S/4 и т.д. Проходы копирования в этой процедуре нежелательны, так как они не уменьшают числа отрезков. Можно обойтись половиной копирований, используя двухфазную процедуру:
А1: см. Ш1
А2: см. Ш2
А3: скопировать половину отрезков с Т3 на Т1
А4: Слить отрезки с лент Т1 и Т3 на Т2; остановиться, если Т2 содержит только один отрезок.
А5: Скопировать половину отрезков с Т2 на Т1. Вернуться к шагу А2.
Число проходов по всем данным сократилось с 2log
2S до 3/2(log2S) + 1/2, так как в шагах А3 и А5 выполняется лишь "половина прохода", то есть экономится около 25% времени.В действительности можно почти полностью устранить копирование, если начать с F
n отрезков на устройстве Т1 и с Fn-1 отрезков на Т2, где Fn и Fn-1 - последовательные числа Фибоначчи.Эту идею можно обобщить на случай Т лент при любом Т
і 3, используя (Т-1)-путевое слияние. Тогда в случае четырех устройств, например, требуется около 0.703log2S + 0.96 проходов по данным. Обобщенная схема использует обобщенные числа Фибоначчи. Теперь необходимо решить несколько вопросов:Точные финобаччиевы распределения можно получить, "прокручивая" рассмотренную схему в обратную сторону, циклически переставляя содержимое устройств. В общем случае, если положить Р = Т - 1, распределения в многофазном слиянии для Т устройств будет аналогично соответствовать числам Финобаччи Р-го порядка. В точном распределении n-го уровня на k-ом устройстве будет:
F(P)n+P-2 + F(P)n+P-3 + … + F (P)n+k-2
Начальных отрезков для 1
Ј k Ј P, а общее количество начальных отрезков на всех устройствах будет, следовательно, равноtn - PF(P)n+P-2 + (P - 1)F(P)n+P-3 + … + F(P)n-1
Это решает вопрос о "точном фибоначчиевом распределении". Но что мы должны делать, если S не равно в точности t
n ни при каком n? Как первоначально поместить отрезки на устройства?|
|
|
Рис.4 Схема многофазного слияния |
Если S не является точным числом Фибоначчи (а чисел Фибоначчи не так уж и много), то можно действовать, как в сбалансированном Р-путевом слиянии, добавляя "фиктивные отрезки"; поэтому можно считать, что S, в конце концов, будет точным. Способов добавления фиктивных отрезков несколько.
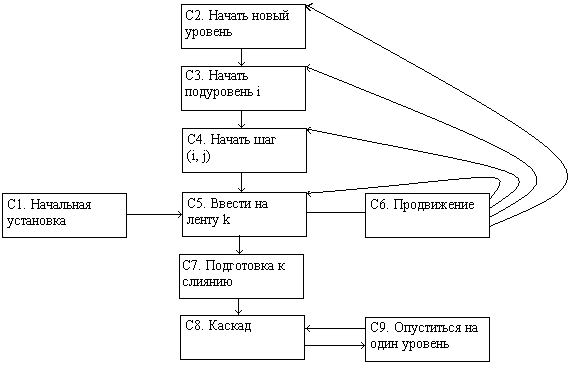
Другая основная схема, называемая каскадным слиянием, на самом деле была открыта раньше многофазной. Сделано это было Б. К. Бетцом и У. К. Катте в 1956 году.
Каскадное слияние, подобно многофазному, начинается с "точного распределения" отрезков по , хотя правило точного распределения отличны от вышеуказанных. Ясно, что операции копирования излишни, и их можно было бы опустить. Фактически, однако, в случае 6 устройств это копирование занимает только небольшой процент всего времени.
На первый взгляд может показаться, что каскадная схема - довольно плохой вариант в сравнении с многофазной, так как стандартная многофазная схема использует все время (Т - 1)-путевое слияние, в то время, как каскадная использует (Т - 1)-путевое, (Т - 2)-путевое, (Т - 3)-путевое и т.д. Но в действительности она асимптотически лучше, чем многофазная, для 6 и более устройств! Как мы видели в п.2, высокий порядок слияния не является гарантией эффективности. В таблице 1 показаны характеристики выполнения каскадного слияния. Нетрудно вывести "точное распределение" для каскадного слияния. Для шести устройств имеем такой порядок:
|
Уровень |
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
|
0 |
1 |
0 |
0 |
0 |
0 |
|
1 |
1 |
1 |
1 |
1 |
1 |
|
2 |
5 |
4 |
3 |
2 |
1 |
|
3 |
15 |
14 |
12 |
9 |
5 |
|
4 |
55 |
50 |
41 |
29 |
15 |
|
5 |
190 |
175 |
146 |
105 |
55 |
|
… |
… |
… |
… |
… |
… |
|
N |
An |
Bn |
Cn |
Dn |
En |
|
N+1 |
An+Bn+Cn+Dn+En |
An+Bn+Cn+Dn |
An+Bn+Cn |
An+Bn |
An |
Таблица 1. Характер поведения каскадного слияния
|
Ленты |
Проходы (с копированием) |
Проходы (без копирования) |
Отношение роста |
|
3 |
2.078lnS + 0.672 |
1. 504lnS + 0.992 |
1.6180340 |
|
4 |
1.235lnS + 0.754 |
1.102lnS + 0.820 |
2.2469796 |
|
5 |
0.946lnS + 0.796 |
0.897lnS + 0.800 |
2.8793852 |
|
6 |
0.796lnS + 0.821 |
0.773lnS + 0.808 |
3.5133371 |
|
7 |
0.703lnS + 0.839 |
0.691lnS + 0.822 |
4.1481149 |
|
8 |
0.639lnS + 0.852 |
0.632lnS + 0.834 |
4.7833861 |
|
9 |
0.592lnS + 0.851 |
0.587lnS + 0.845 |
5.4189757 |
|
10 |
0.555lnS + 0.869 |
0.552lnS + 0.854 |
6.0547828 |
|
20 |
0.387lnS + 0.905 |
0.397lnS + 0.901 |
12.4174426 |
Отметим интересное свойство этих чисел: их относительные величины являются также и длинами диагоналей правильного (2Т-1)-угольника. Например, пять диагоналей одиннадцатиугольника имеют относительные длины, очень близкие к 190, 175, 146, 105 и 55! Кроме того, относительные времена, затрачиваемые на (Т-1)-путевое слияние, (Т-2)-путевое слияние, …, однопутевое слияние приблизительно пропорциональны квадратам длин этих диагоналей.
|
|
|
Рис. 5 Каскадное слияние со специальным распределением |
Еще один подход к сортировке слиянием был предложен Шелдоном Собелем в 1962 г. Вместо того, чтобы начинать с распределения, когда все начальные отрезки распределяются по устройствам, он предложил алгоритм, который переключается то на распределение, то на слияние, так что большая часть сортировки происходит еще до того, как вся исходная информация будет полностью просмотрена.
Предположим, например, что для слияния используется пять лент. Рассматриваемый метод начинает с записи по одному начальному отрезку на каждую из четырех лент и сливает их (читая в обратном направлении) на пятую ленту. Опять возобновляется распределение, на этот раз циклически сдвинутое на 1 вправо по отношению к лентам, и второе слияние дает еще один отрезок. Когда этим способом сформированы четыре отрезка, дополнительное слияние создает отрезки А. Процесс можно продолжать, создавая еще три отрезка А, сливая их в очередные и т.д. до тех пор, пока не исчерпаются исходные данные. Длину исходных данных заранее знать не нужно.
Если число начальных отрезков есть 4
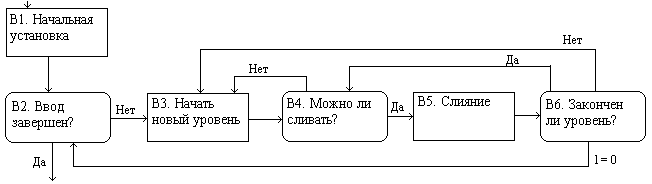
m, то нетрудно видеть, что этот метод обрабатывает каждую запись ровно m+1 раз (один раз во время распределения и m раз во время слияния). Если S лежит между 4m-1 и 4m, то можно с помощью фиктивных отрезков увеличить S до 4m; следовательно, общее время сортировки будет определяться как log4S + 1 проходами по всем данным. Это как раз то, что достигается при сбалансированной сортировке на восьми лентах; в общем случае осциллирующая сортировка с Т рабочими лентами эквивалентна сбалансированному слиянию с 2(Т - 1) лентами. Если S оказывается степенью Т – 1, то это самый лучший вариант, который можно получить при любом методе с Т лентами, так как здесь достигается нижняя оценка. Но если S больше этой степени хотя бы на единицу, этот метод теряет почти целый проход.Некоторое усовершенствование метода было предложено в 1966 году Деннисом Л. Бэнчером, который назвал свою процедуру перекрестным слиянием. Основная цель его состоит в том, чтобы отложить слияние до тех пор, пока не будет накоплено больше сведений об S.
Точное описание алгоритма Бэнчера приводится ниже на рис. 6. К сожалению, соответствующую процедуру сложнее понять, чем запрограммировать; легче объяснить этот метод ПК, чем программисту! Частично это происходит по той причине, что рекурсивный метод выражен в итеративном виде и затем подвергнут некоторой оптимизации: порой необходимо несколько раз проследить за работой алгоритма, чтобы понять, что происходит.
|
|
|
Рис.6 Осциллирующая сортировка с перекрестным распределением |
Григорьев Григорий, группа П-13
4-15 марта 2001 г.